C++ Local HTTP Inference
The local inference service allows you to perform model inference via local HTTP requests and obtain results.
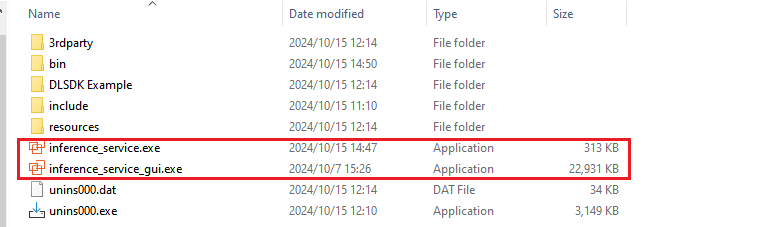
In the installation directory, you will find inference_service.exe and inference_service_gui.exe.
Double-click inference_service.exe to start the inference service in the background. You can find it in the system tray. inference_service_gui.exe will open the graphical user interface (GUI) for the service (ensure inference_service.exe is running first).
Using the Graphical Interface
You can register and remove your models using the graphical interface.
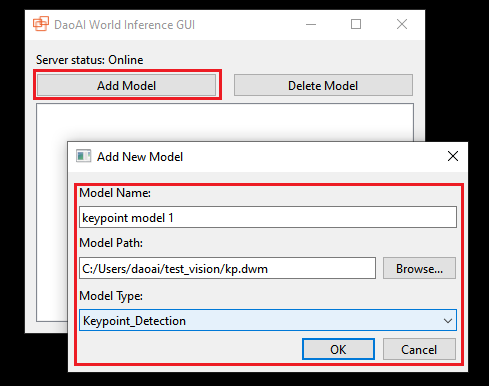
Click Add Model to register a model, input the model name, select the model path, and choose the model type. Click OK to register the model.
To delete a model, select a model and click Delete Model.
Using HTTP Requests
You can manage your models and execute model inference via HTTP requests sent to localhost:5000.
There are four requests available. Below is an example using Postman.
Register Model:
Post localhost:5000/register
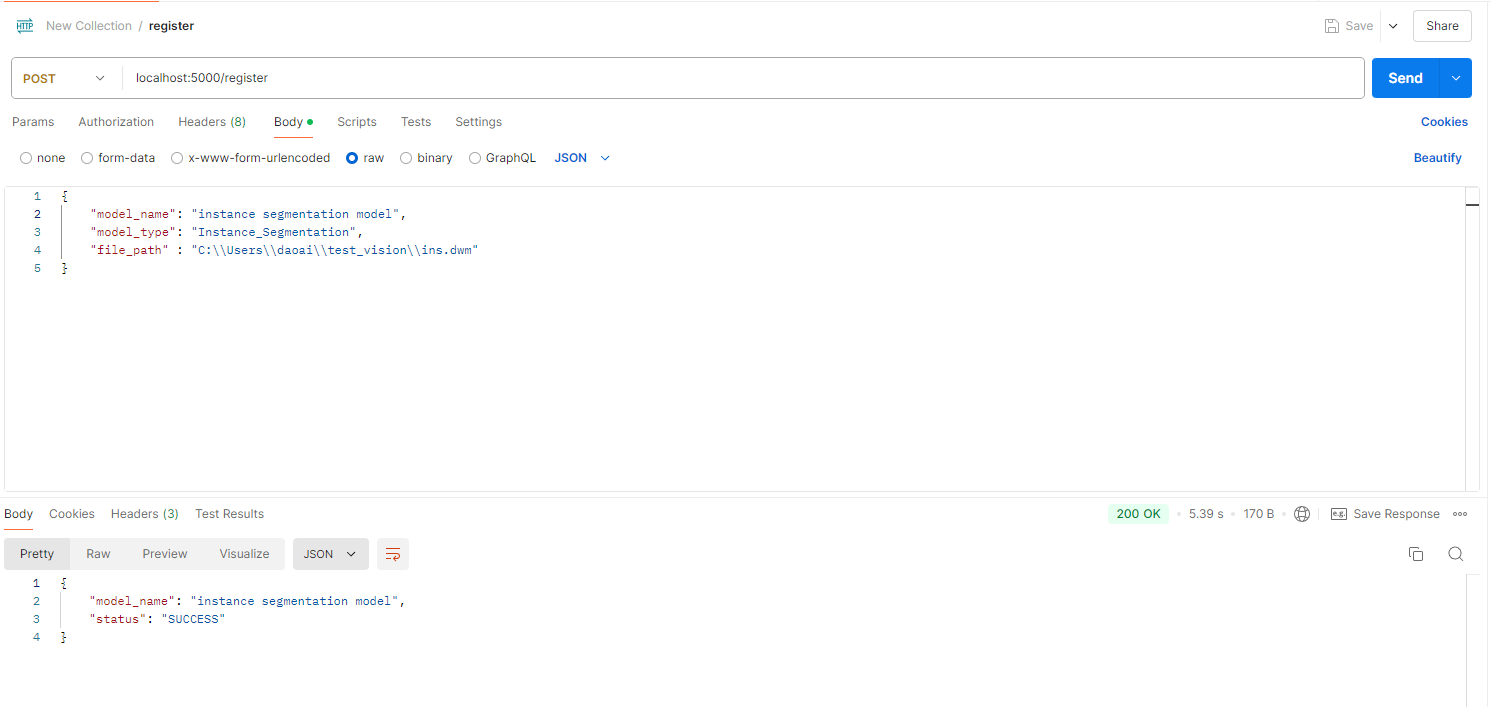
This command registers a local model with the inference service for future use.
List Models:
GET localhost:5000/list
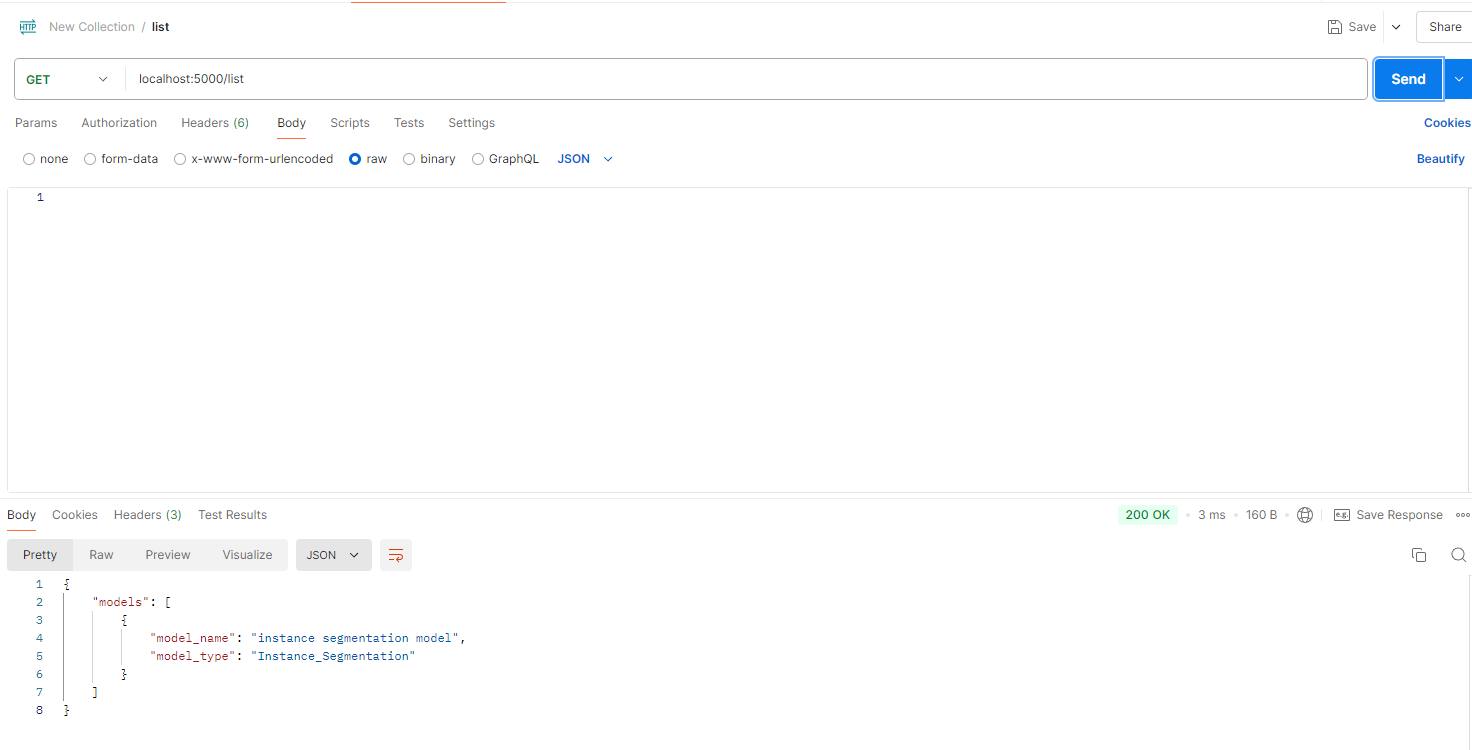
This command lists the models that have already been registered.
Model Inference:
Post localhost:5000/inference
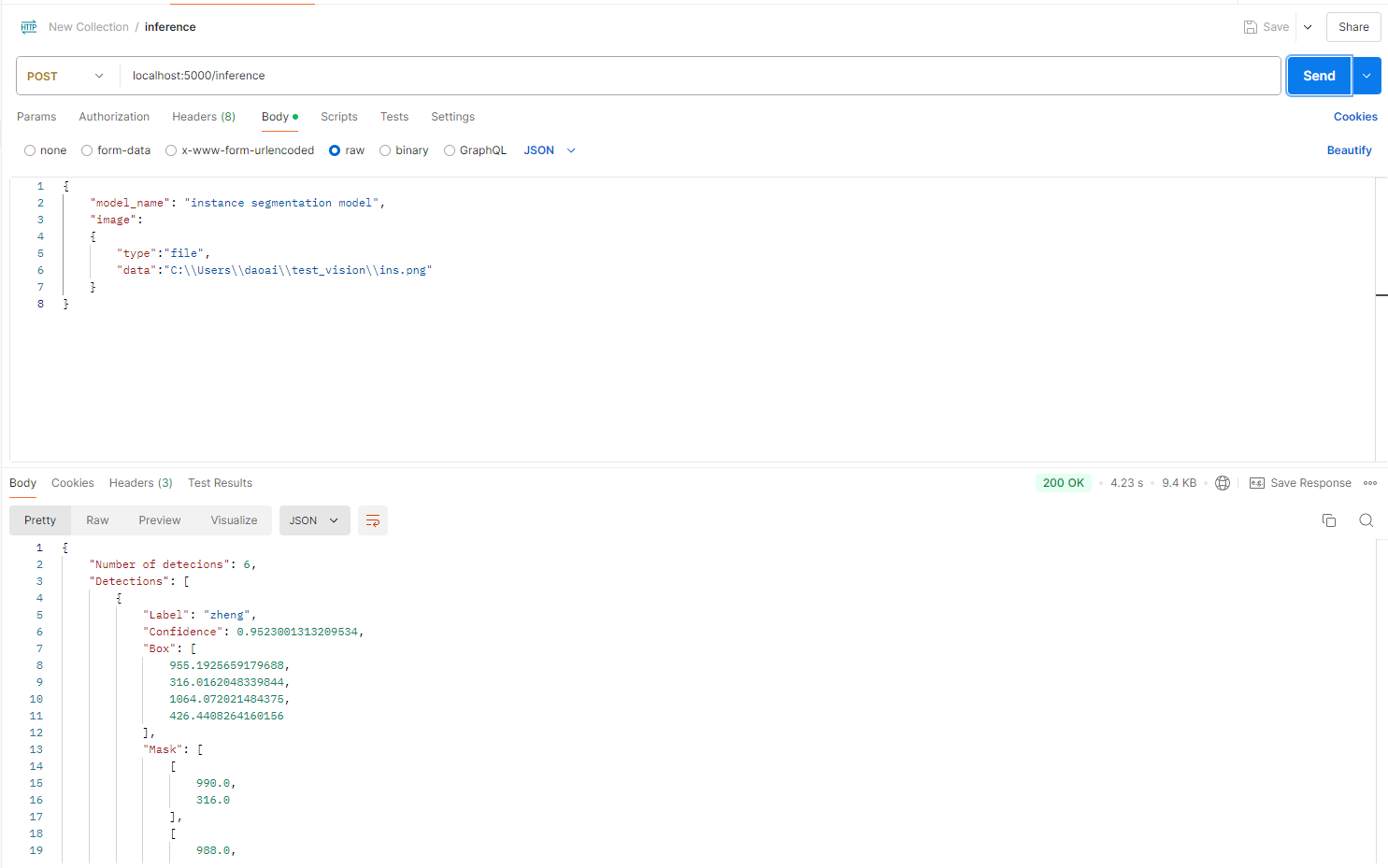
This command specifies a model and a local image path, then returns the inference result for the image with the specified model.
Delete Model:
DELETE localhost:5000/delete
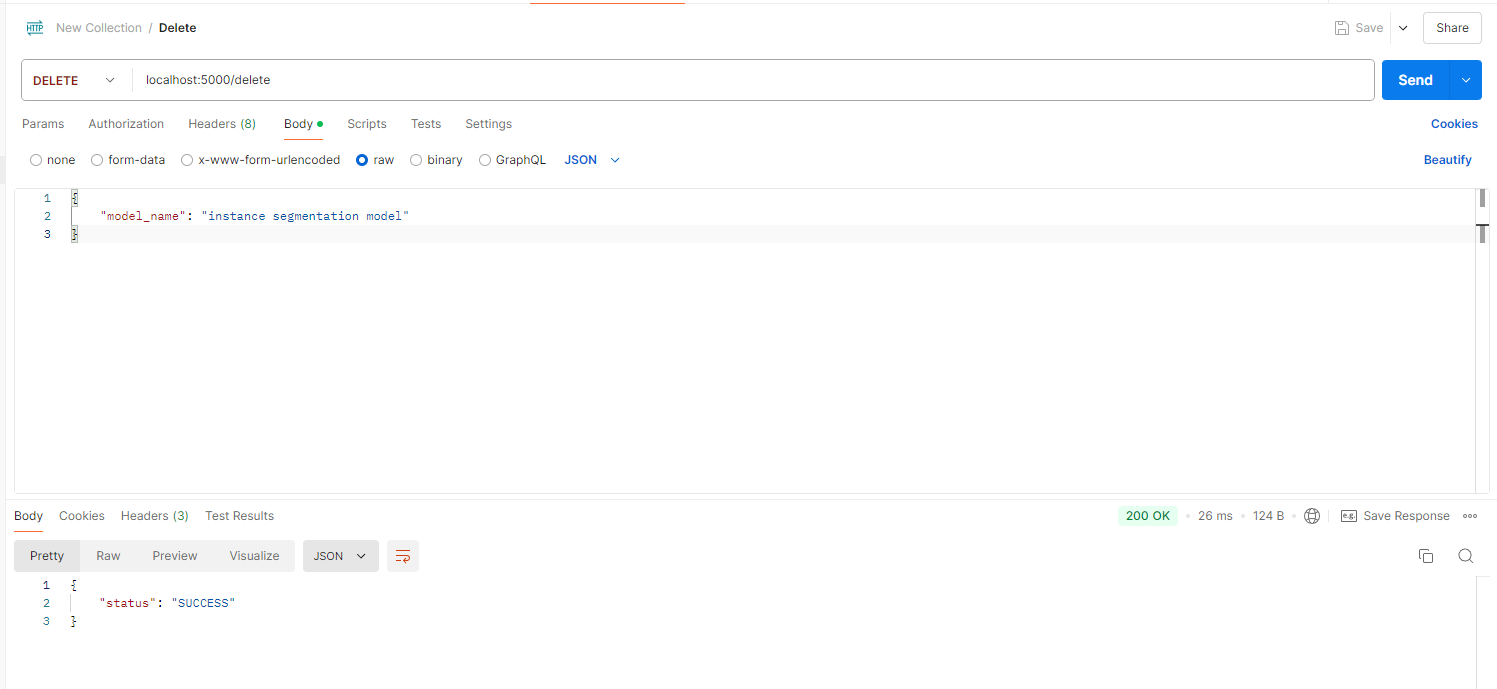
This command removes the specified model from the inference service (without deleting the local model file).
Example Project
The C++ Inference Client simplifies environment configuration dependencies by interacting with the Inference Service.
Compared to the Windows C++ SDK, which requires many DLL dependencies, the C++ Inference Client only needs one. This avoids DLL version conflicts when introducing other dependencies (like OpenCV) into the project.
The C++ Inference Client provides the same interface as the Windows C++ SDK.
You can find the C++ Inference Client Example Project at "C:\Program Files\DaoAI World SDK\InferenceClient\InferenceClientExample" in the installation directory.