OCR
OCR (Optical Character Recognition) is used for extracting text from images.
After completing the model annotations, refer to the video in the Training section to create dataset versions and train/deploy the model.
Use Case Scenarios
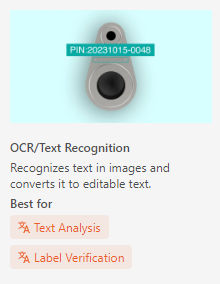
OCR can recognize and extract text from images.
For example, product numbers, dates, names, and other information can be quickly extracted using an OCR model.
In most cases, users do not need to train the model themselves; they can simply download the pre-trained model from playground and use it for most scenarios. Additional training should only be considered if the performance is not satisfactory.
Pre-trained OCR models can be found and downloaded from the model experience section.

Annotation Methods
You can use a pre-trained OCR model to assist with annotation, allowing the deep learning model to help you annotate, and then manually check and correct the annotations
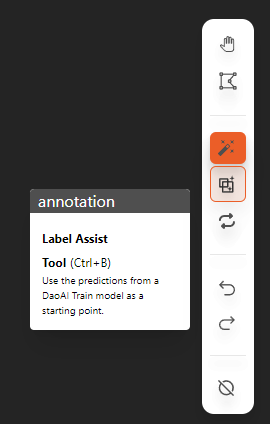
When annotating, use the rectangle annotation tool or smart polygon tool to outline the text area. Then enter the corresponding text as the label name

Repeat the annotation for all text in the scene. If there is no text in the scene, annotate it as empty.
Practice
Download the practice dat with ocr.zip
After extracting, you will find 11 images and annotation (.json) files. Please upload only the images to DaoAI World for annotation practice. Afterward, you can upload both images and annotation files to compare results.