非监督缺陷分割
非监督缺陷分割 是一种正常数据训练的模型,能够识别物体是否处于异常 (NG) 状态,例如破损、变形等问题。
非监督缺陷像素级检测可仅用 一张正常样本 完成模型训练,实现对各类未知缺陷区域的精准定位与分割。

完成模型训练后,可参考 训练 章节下的视频,创建数据集版本并部署模型。
适用场景
非监督缺陷分割 适用于以下场景:
单一物体:数据集中仅包含一种物体,且该物体的位置需要保持相对固定。
异常检测:物体处于正常或异常 (NG) 两种状态,能够判断物体是否发生了破损、变形等变化。
模型检测模式
非监督缺陷分割 模型支持以下2种检测模式,可根据场景需求选择:
图像级 - 分析图像的若干特定区域,判断目标区域是否存在缺陷。
像素级 - 在图像的若干特定区域中对每个像素进行分析,标注出异常区域。
标注方法
非监督缺陷分割项目中,每种模型检测模式的标注方式有所不同,具体如下:
图像级 首先,定义一个标准图片并在图片上框选出检测区域,保存后即作为模板。由于非监督检测要求物体位置保持相对固定,所有图片的检测区域都应覆盖相同的待检测部件。

标注时,依次点击检测区域并标注为 OK 或 NG。
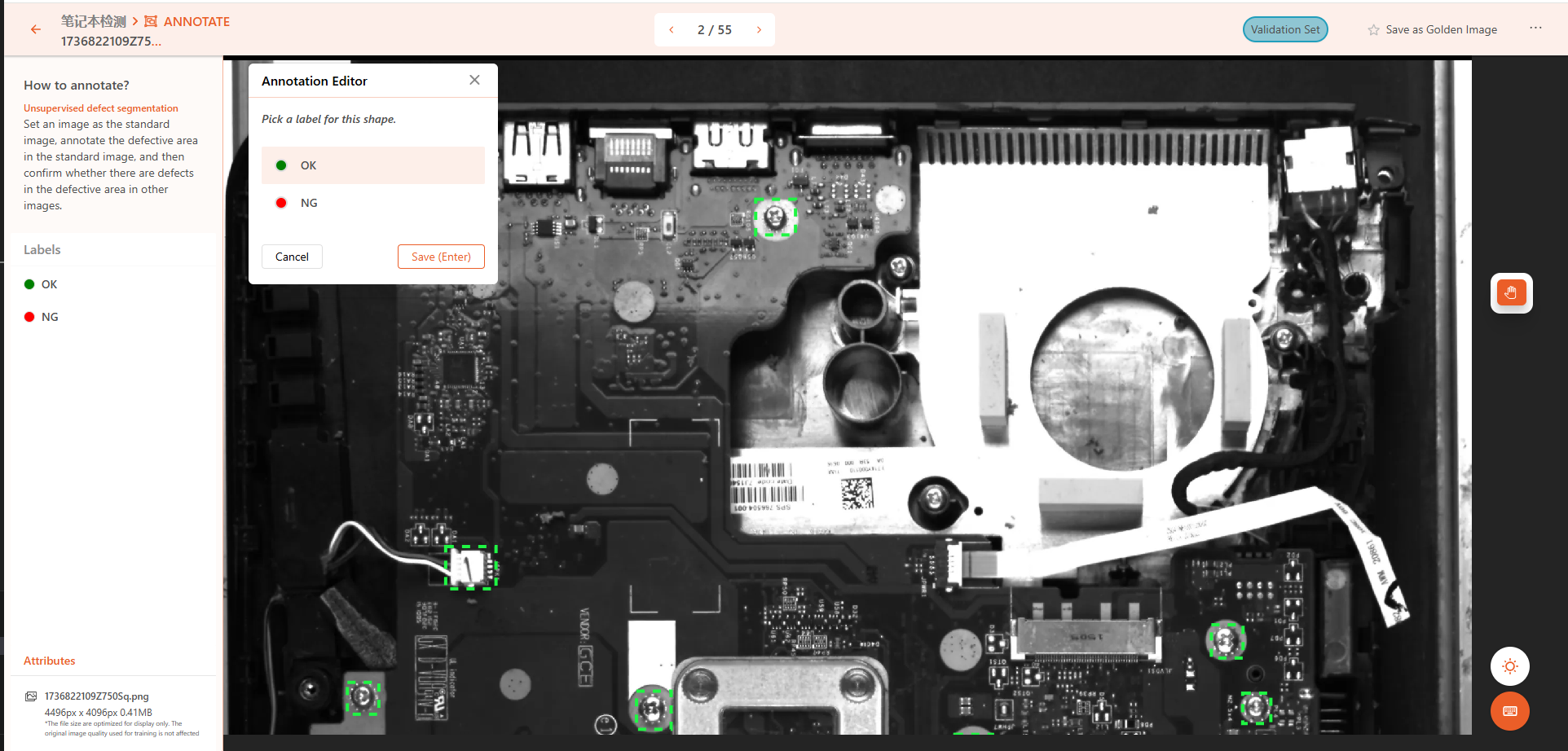
像素级 首先,定义一个标准图片并框选出检测区域,保存后即作为模板。
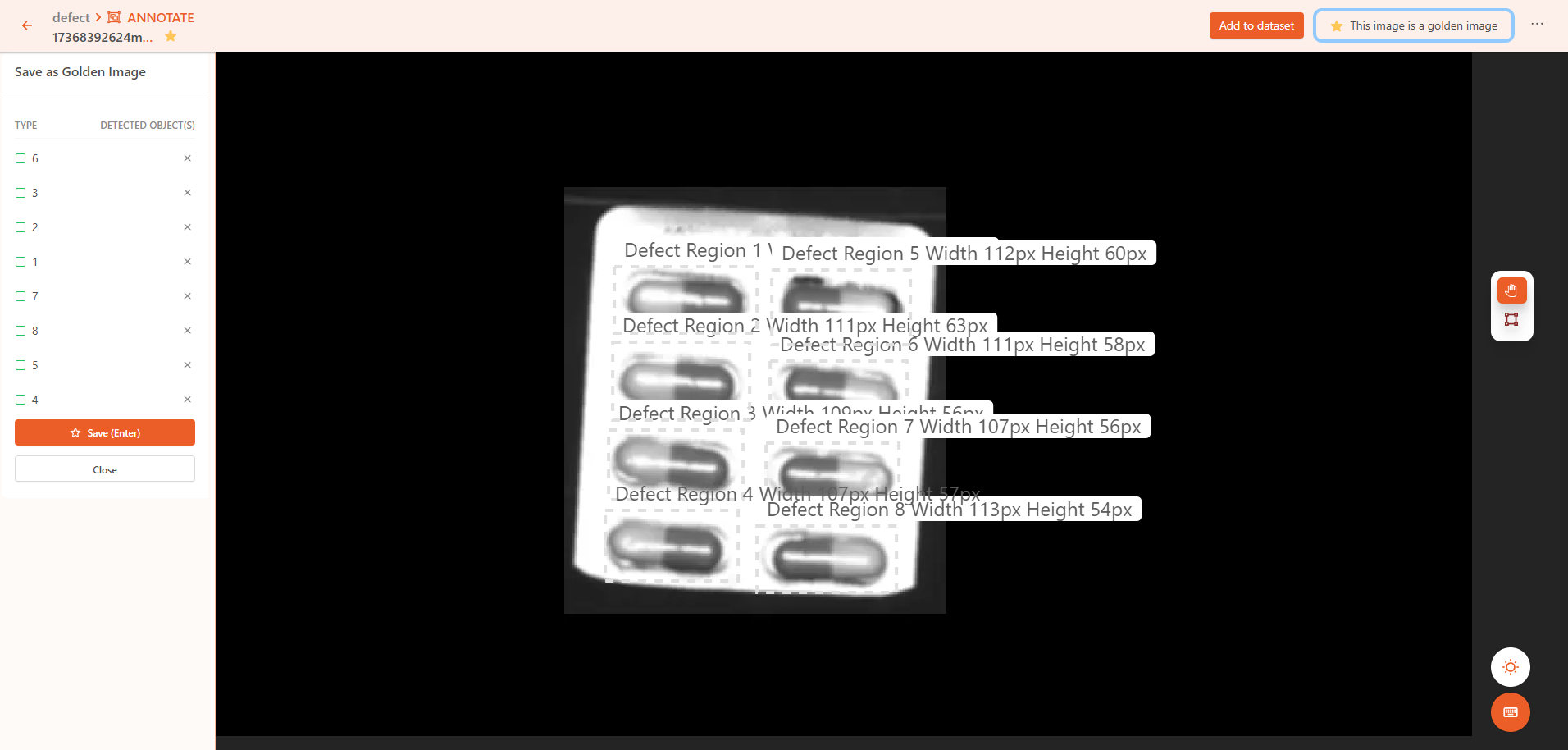
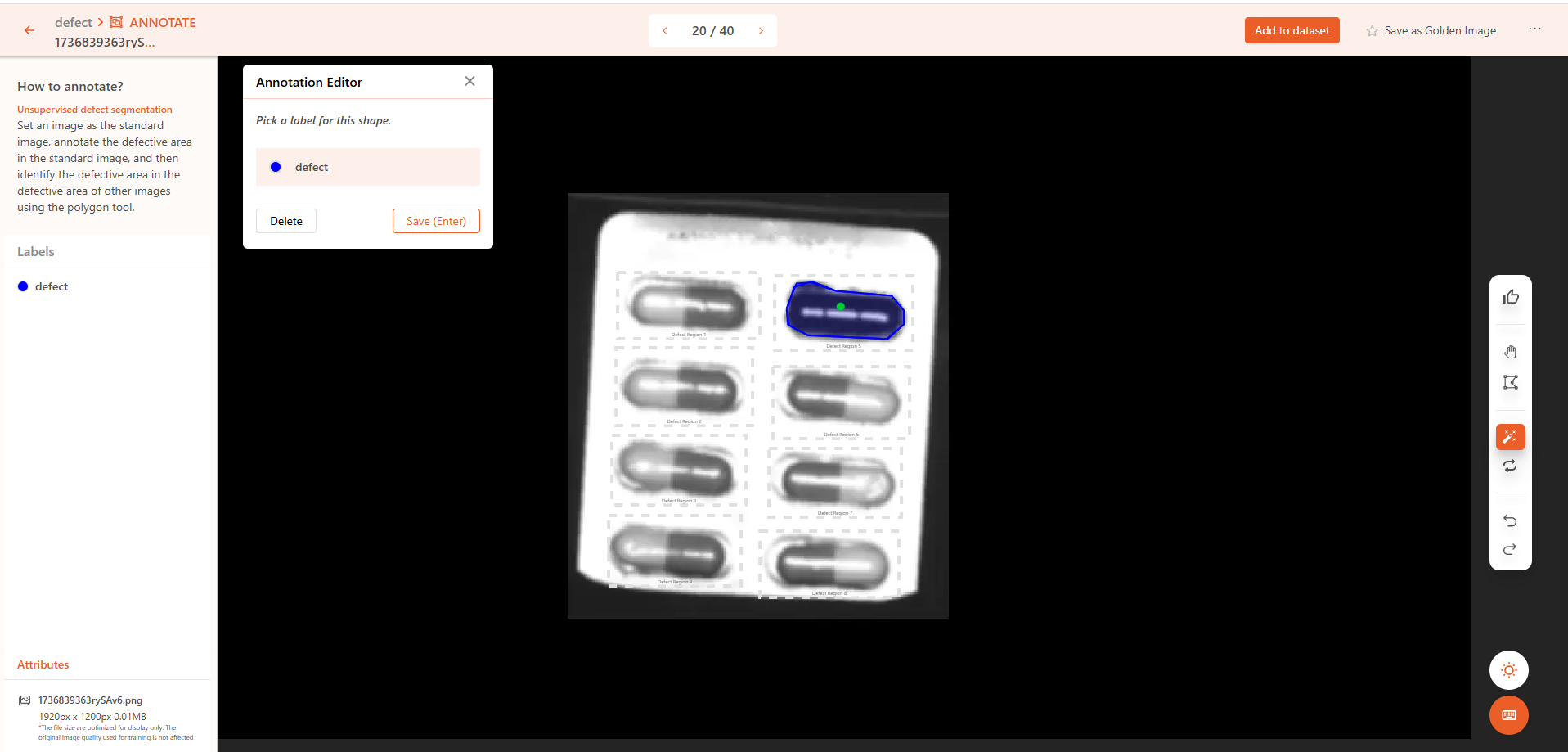
使用智能标注工具或多边形工具,标注检测区域内的缺陷轮廓。如果图片无缺陷,则将其标注为无缺陷。
注意事项
正常样本训练 训练集中只会用到正常样本训练,准确的说,是只会用到一张标准图片来训练,其余的正常数据会帮助模型判断出一个合理的正常样本的阈值。
备注
模型预测时会得出一个AI偏离值(AI Deviation Score) ,这个值代表了模型判断的当前样本与正常样本的相似度,范围在0-1.
0 代表标准样本,而接近0的值代表接近与正常样本。
1 代表异常样本,接近1的值就代表与正常样本相差越多,也就是异常样本。
模型会基于训练集,合理的设置一个区分阈值,低于该阈值的样本会被视为正常,而高于该阈值的样本会被视为异常。
数据一致性 正常图片的检测区域内不应包含任何缺陷,否则可能导致训练失败或结果不理想。
多缺陷支持 如果一个物体存在多个缺陷,可以为每个缺陷单独标注区域。
默认配置 非监督缺陷分割模型训练时,不默认添加任何数据增强选项。
训练模式 非监督缺陷分割的训练模式分为快速和准确,快速会将每个检测区域压缩至256×256的大小,而准确会将每个检测区域压缩至512×512的大小进行训练。如果您的图片分辨率非常高,那么建议您划分出若干个小一点的检测区域来缩小每个检测区域的分辨率。
练习
从以下链接下载练习数据 unsupervised_data.zip: 练习数据
解压后,您将获得 11 张图片及其标注文件(.json)。 - 上传图片至 DaoAI World 进行标注练习。 - 完成标注后,可将图片和标注文件一同上传,验证模型训练效果。