深度学习
DaoAI InspecTRA中,用户可以加入深度学习功能,接下来本页将提供有关如何使用深度学习的说明。
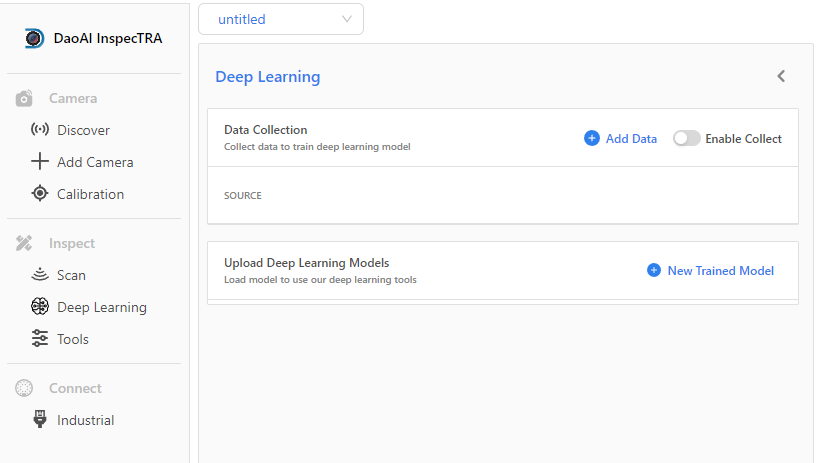
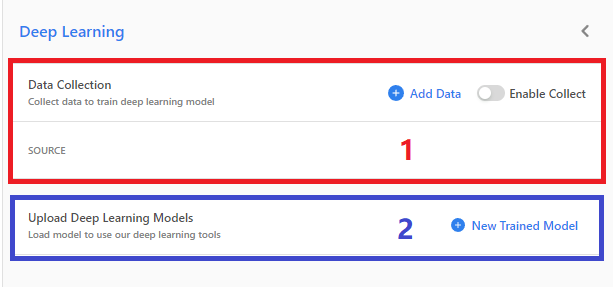
深度学习有两个部分组成,第一个部分数据收集功能部分,第二个部分为添加模型进行识别。
深度学习数据采集
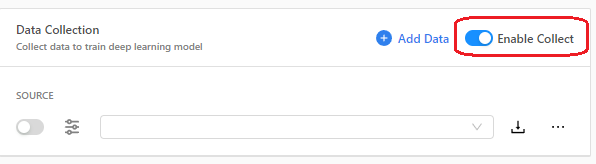
启用数据收集功能的时候,必须要把 "Enable Collect" 选项打开。
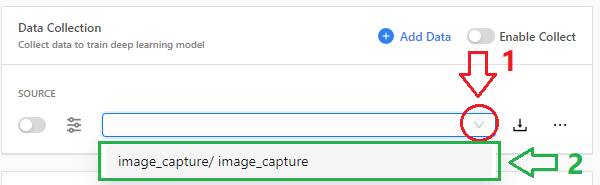
点击打开下拉式菜单;
选择用于收集数据的相机;
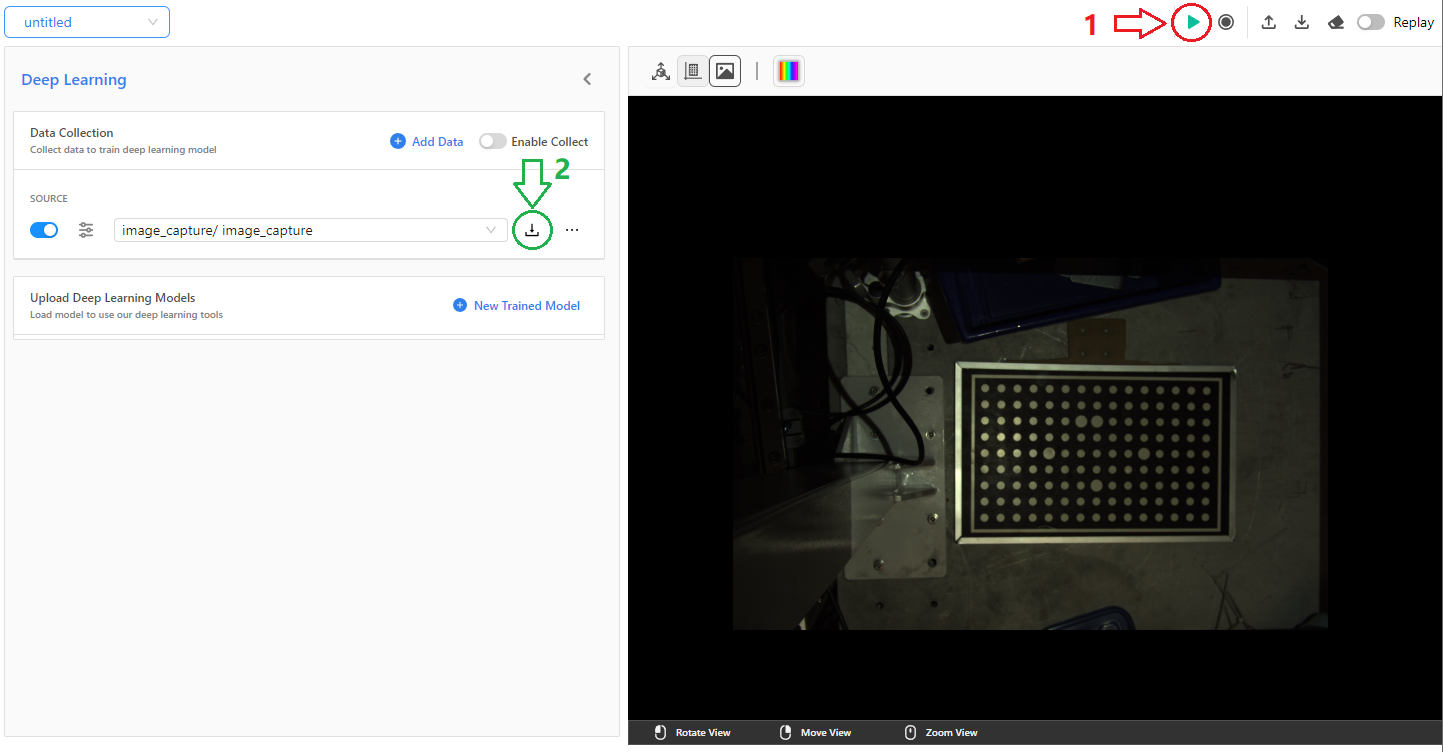
收集数据功能必须连接相机,设置好上述步骤后,需要使用相机拍照:
点击拍摄,相机采图;继续点击拍摄,直到拍摄完所有数据;
点击下载按钮,下载文件;

下载后的文件会是一个没有后缀的文件,类似上图显示的名字。你可以使用解压软件(7zip等)把此文件解压。
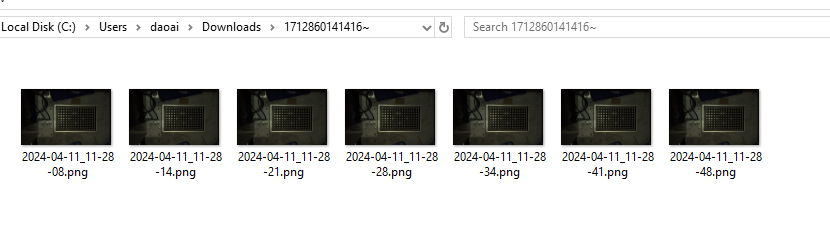
解压后,打开文件夹,之前拍摄的数据都会在这里。
深度学习模型
第二部分,是使用收集好的数据,使用DaoAI DeepWorld进行标注和训练。加载至DaoAI InspecTRA。

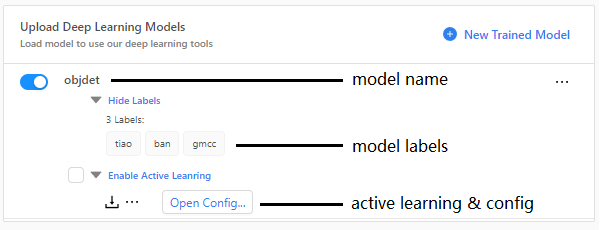
深度学习模型加载后,如上图显示,你可以看到模型的名字、标签和设置按钮。
模型名字旁边的切换按钮,是启用或者禁用模型的选项。
标签是显示当前模型中的所有标签及其数量。
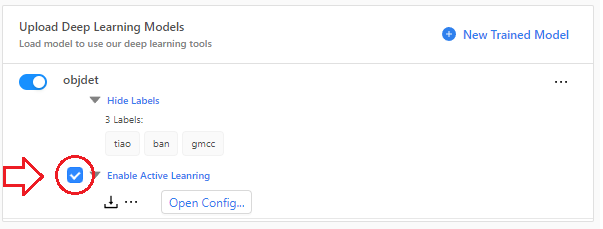
启用或者禁用主动学习功能,下载主动学习功能的数据。
点击按钮 "Open Config",你可以对于主动学习功能进行设置。
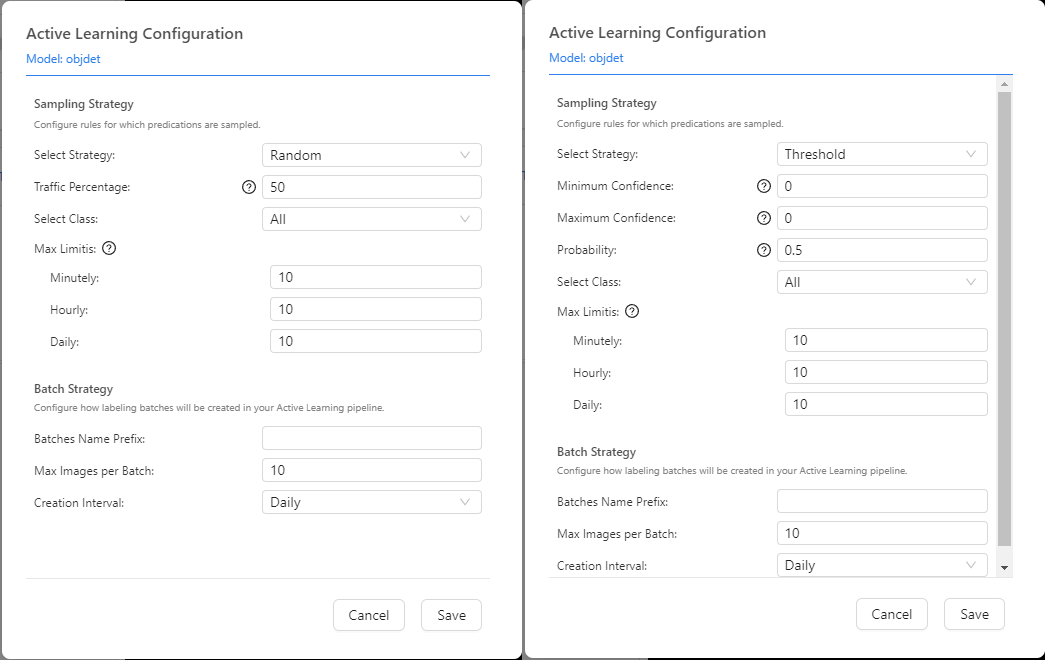
点击后,设置菜单打开如上图所示。一共有两个主动学习的策略:随机采集(左)和临界点采集(右)。
随机采集是按照设定的参数进行随机采样。
临界点采集是按照设定的参数,对数据进行识别,根据其识别结果是否达到临界范围内进行采集。
参数设置详情如下:
- 策略
目前支持的策略为两种:随机采集和临界点采集。
- 随机度
此数值为随机数据中,被保存数据的数量,在总数量百分比。例子:随机度为50,达标的采集数据中,有一半的数据会被保留;随机度为100,达标的采集数据中,所有的数据会被保留。
- 最小置信度
采集的数据中,只有识别结果大于此数值的数据,才属于达标,才能保存。
- 最大置信度
采集的数据中,只有识别结果小于此数值的数据,才属于达标,才能保存。建议此数值设置为 1。
- 几率
此数值和随机采集中的随机度一样,不过仅用于临界点采集策略。此几率能提高数据的随机性。
- 选择标签
选择想要采集的数据的标签。通常用于收集某些特定的种类的物体,或者选择所有物体 "all"。
- 收集限制
此参数为控制数据收集的最大数量。限制数据收集数量过大,导致内存或者电脑容量不够。
分钟:限制每分钟保存的数据最大值。
小时:限制每小时保存的数据最大值。
每天:限制每天保存的数据最大值。
- 数据名称
输入该主动学习保存的数据集名称。
- 数据集最大值
输入该主动学习保存的数据集的最大值。
- 数据收集频率
主动学习保存的数据集的频率,分别为:每天,每周和每月。配合"数据集最大值"使用,在此频率内保存的数据集最多不能超越该设置。
保存主动学习采集数据,点击该按钮可把数据下载。
下载后的文件会是一个没有后缀的文件,类似上图显示的名字。你可以使用解压软件(7zip等)把此文件解压。解压后,打开文件夹,之前采集的数据集和自动标注数据都会在这里。