训练
创建新训练集
创建新训练集功能是用标注过的图片创建一个训练集,用来训练深度学习模型。在此功能中你可以划分训练集测试集比例,添加预处理与数据增强等操作。不同的训练集会有 不同的版本,我们可以通过查看不同的版本的训练结果,来对比不同图像,预处理和数据增强对训练结果的影响。
如何创建新数据集
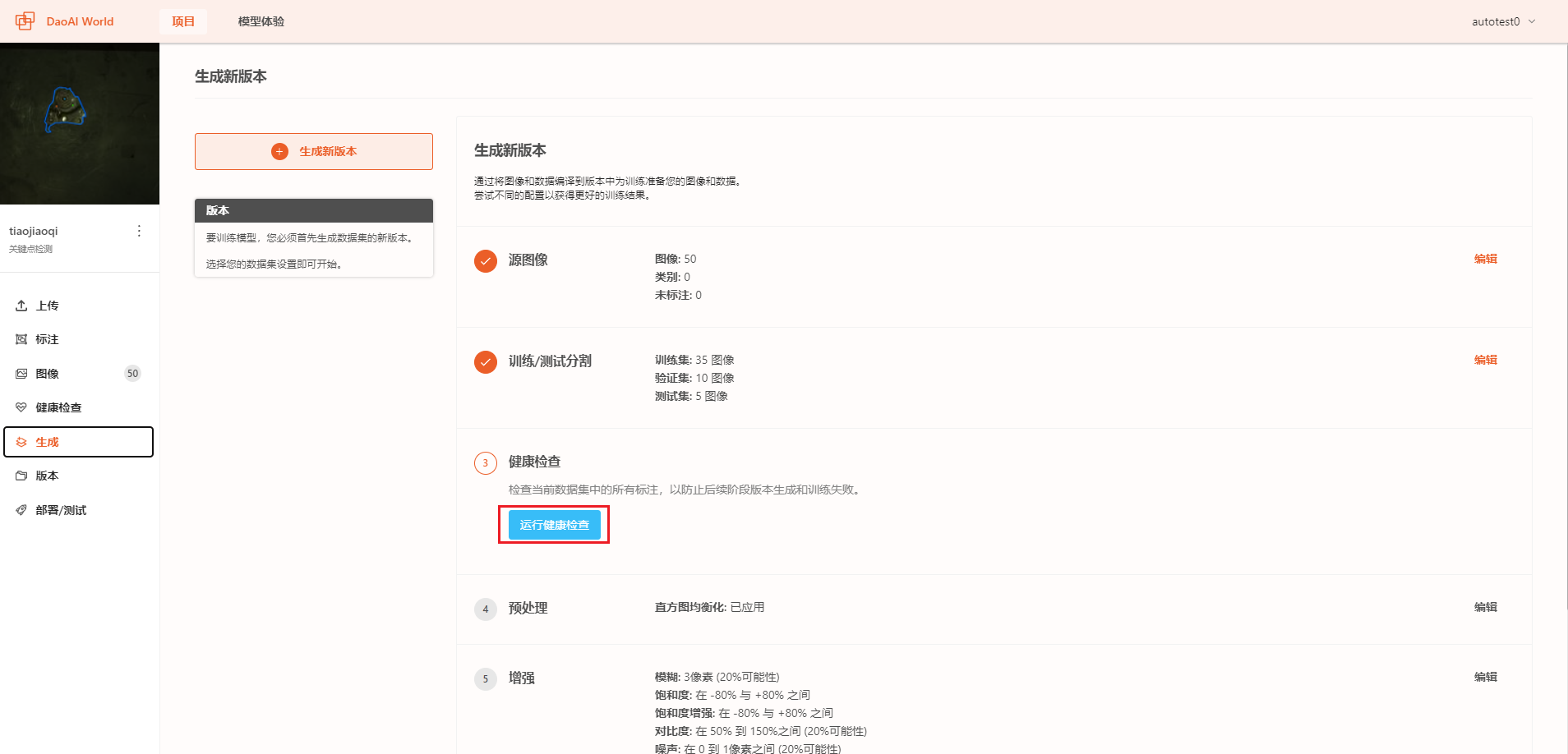
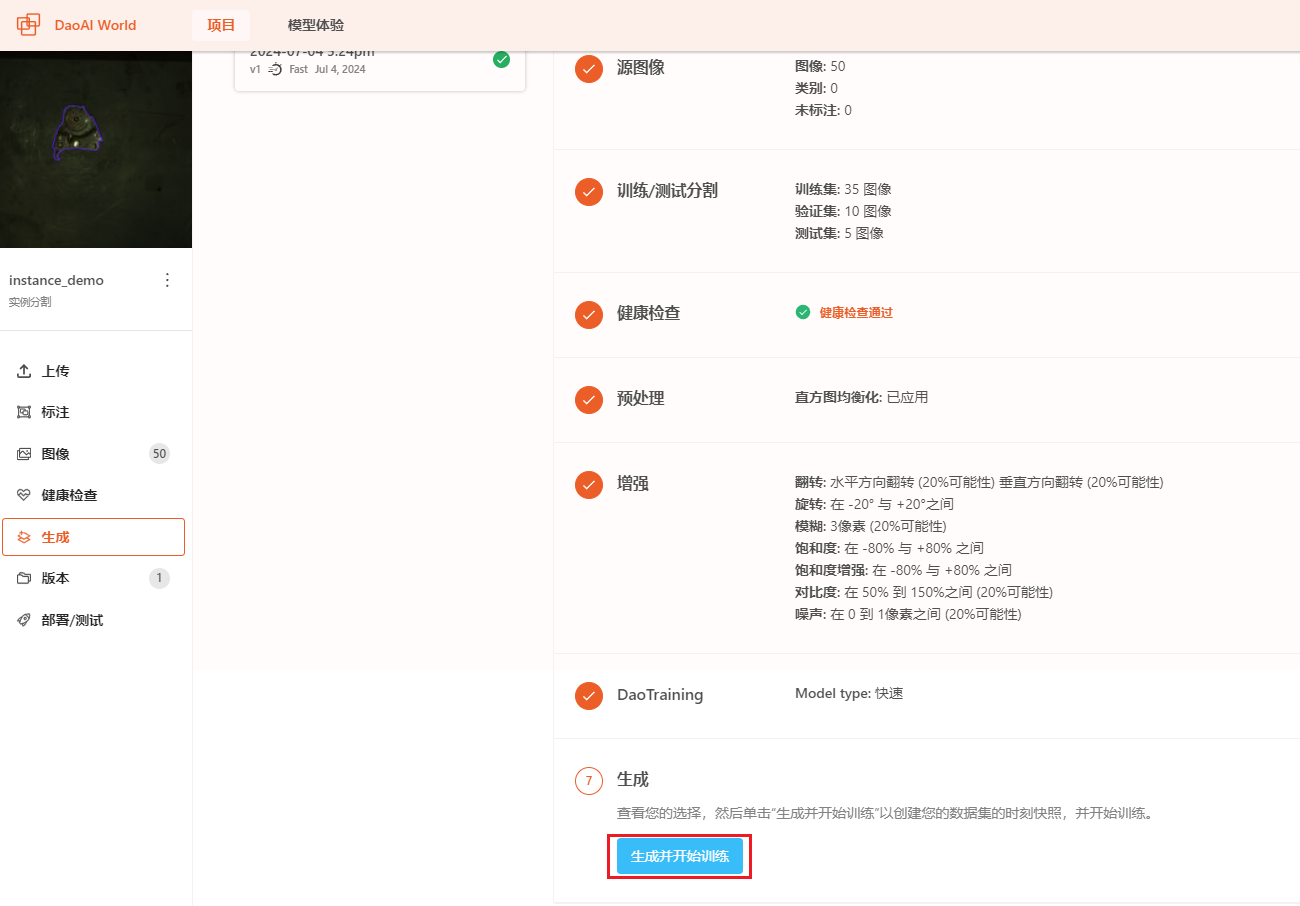
要创建新的数据集,请单击DaoAI World项目界面的侧栏中的 创建 。然后,在此界面中,您可以分配训练/测试集比例(可选,一般默认的为7:2:1原则)。在添加预处理和数据增强之前,需要生成数据集报告,该报告将会检测数据集中存在的标注问题,如标签错误,标签缺失等。
重新调整训练/测试集
在新数据集的创建过程中,您还可以重新调整训练,验证和测试集的比例。如果您需要这么做,请转到 分配训练/测试集,并单击”重新平衡 按钮。

在数据集报告检测完成并通过后(即数据集中无无效标注),您可以为您的训练添加预处理及数据增强。在部分训练项目中,系统会自动启用部分预处理与数据增强功能,您可以选择关闭或者添加其他的预处理与数据增强功能。
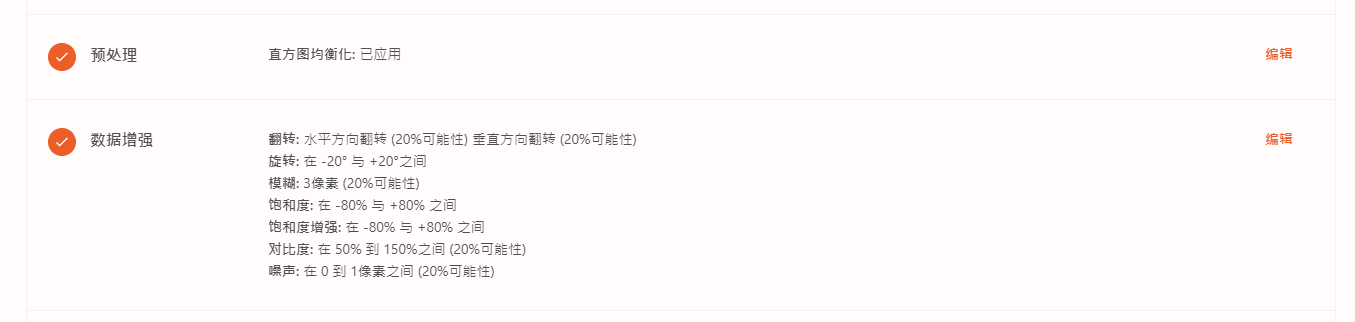
预处理方法
为训练模型准备数据的图像预处理步骤。
备注
预处理可确保您的数据集使用标准格式(例如所有图像的大小相同)这个步骤能够统一数据集保持一致性,增强训练模型的精准度
预处理适用于 训练集 , 有效集 和 测试集 中的所有图像( 增强仅适用于训练集 ) 。
- DAOAI WORLD中提供了以下的预处理选项:
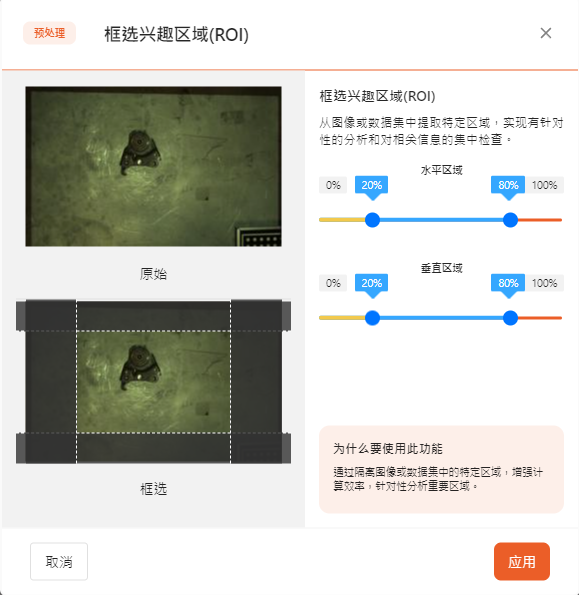
- 感兴趣区域
感兴趣区域会更改图片大小,也可以选择缩放所需的尺寸。 分离感兴趣区域可以从图像或者数据集中提取特定区域,实现有针对性的分析和对相关信息的集中检查。
在弹出的页面中通过调整水平区域与垂直区域中感兴趣的部分来划定范围。该范围会在图像中显示为一个矩形区域,同时该区域会施加在所有的图像上。
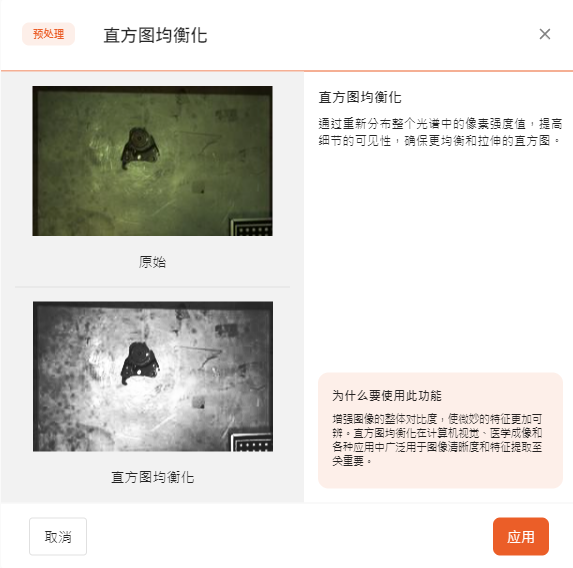
- 直方图均衡化
直方图均衡化是一种用于增强图像对比度的技术。它通过重新分布整个光谱中的像素强度值,调高细节的可见性,确保更均衡和拉伸的直方图。直方图均衡化可以帮助AI模型更好的提取特征值。
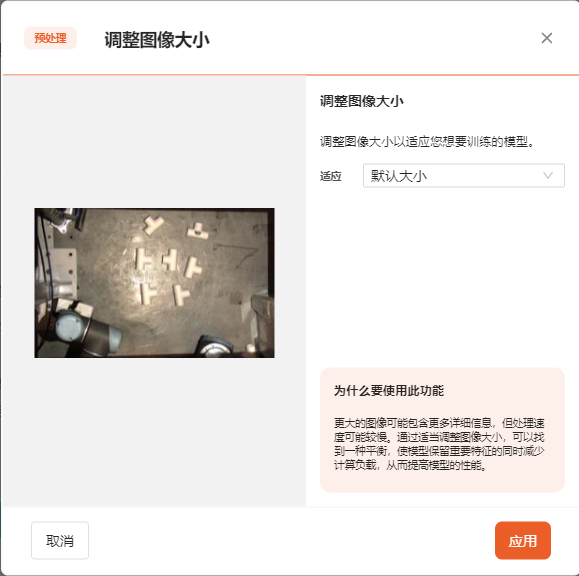
- 调整图像大小
更大的图像可能包含更多详细信息,但处理速度可能较慢。通过适当调整图像大小,可以找到一种平衡,使模型保留重要特征的同时减少计算负载,从而提高模型的性能。
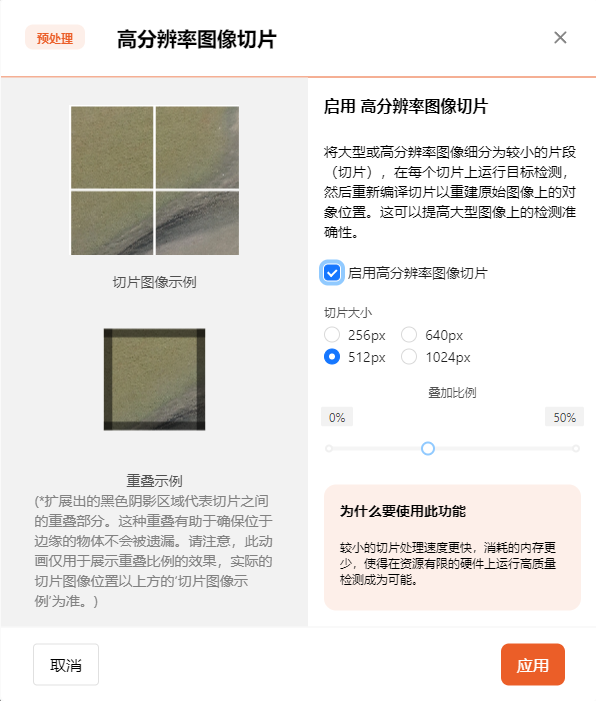
- 高分辨率图像切片功能
对于超高分辨率的图片,传统的训练方式通常需要先对图片进行压缩,但这样会导致细节丢失。而“高分辨率图像切片功能”则通过将图片切割成小块,替代压缩处理,从而在保留完整图像信息的同时,更有效地处理大图像数据,并提高对大型图像的检测准确性。
数据增强方法
使用数据增强功能以提高模型性能
数据增强对现有图像执行变换,并增加数据集中图像的数量。这最终使模型在更广泛的用例范围内更准确。
- DaoAI World支持以下数据增强功能:

备注
我们建议一开始创建一个没有使用数据增强方法的项目。这样您可以评估原始数据集的质量。如果您添加了数据增强方法, 但数据集的性能未达到预期效果,则您将没有一个可以比较模型性能的基线。
如果您的性能在没有使用数据增强的情况下表现不佳,您可能需要研究类别平衡、数据集大小或其他方法。如果您拥有一个数据集并已经成功 训练了没有数据增强的模型时,您可以添加数据增强功能以进一步提高模型性能。
添加数据增强功能
要使用数据增强功能,请转到DaoAI World创建界面中。然后单击 数据增强 为您的数据添加具体的数据增强方法。

增强选项
以下是DaoAI_World支持的数据增强功能。您可以自定义数据增强方法。
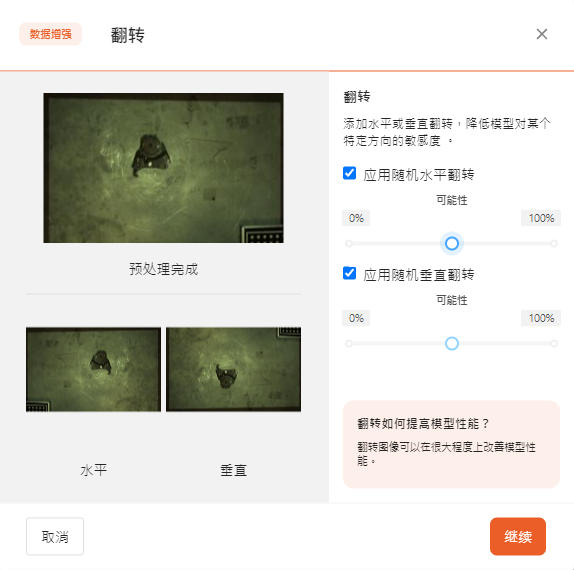
- 翻转
添加水平或垂直翻转,降低模型对某个特定方向的敏感度。
翻转图像可以在很大程度上改善模型性能。
可以选择分别添加水平翻转或垂直翻转,并选择翻转可能性。
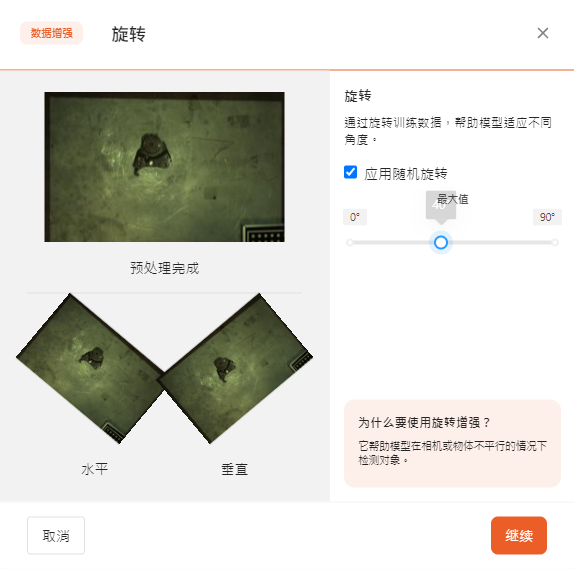
- 旋转
通过旋转训练数据,帮助模型适应不同角度。
它帮助模型在相机或物体不平行的情况下检测对象。
可以通过滑动选择最大旋转角度。
- 缩放
通过变化位置和大小,帮助模型适应对物体和相机位置的平移。
可以通过滑动选择最大缩放比例。
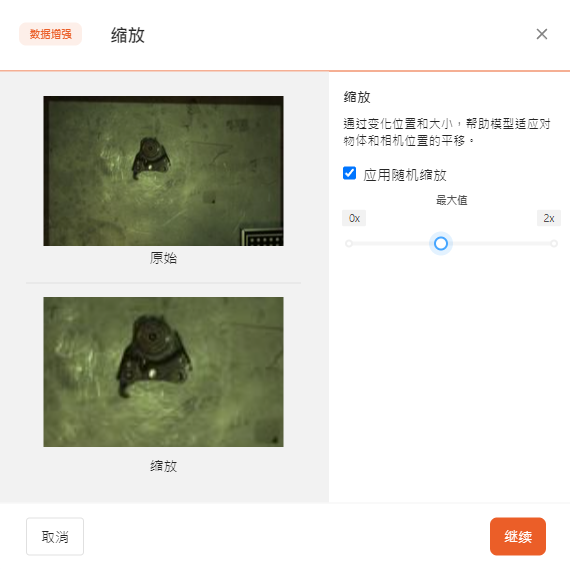
- 剪切变换
通过变化透视,帮助模型适应相机和物体的俯仰和偏斜。
可以通过滑动选择最大剪切比例,剪切变换会同时应用在四个方向上。
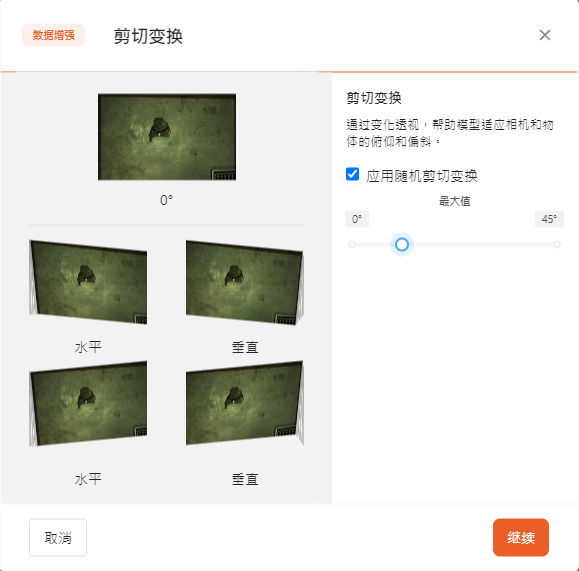
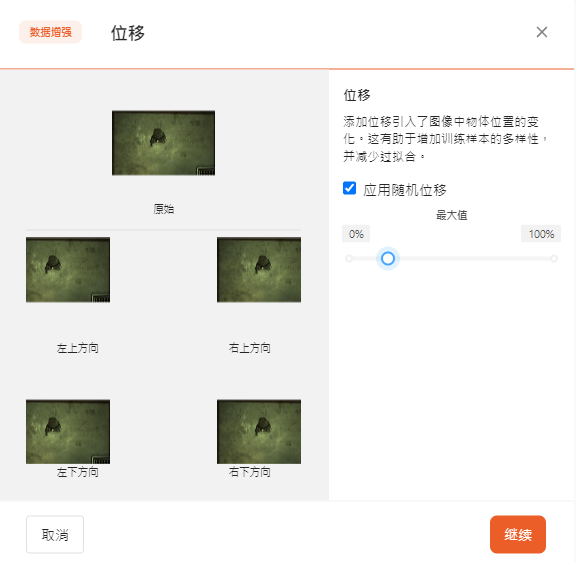
- 位移
位移使图像中物体的位置变化,有助于增加训练样本的多样性,并减少过拟合。
可以通过滑动选择最大位移比例。
- 模糊
通过添加随机的高斯模糊,帮助模型适应相机的不同对焦
当您的物体可能不处于焦点,或者您的模型的边缘不清晰时,可以使用添加模糊提高模型表现。
可以滑动调整模糊的最大像素值及可能性。

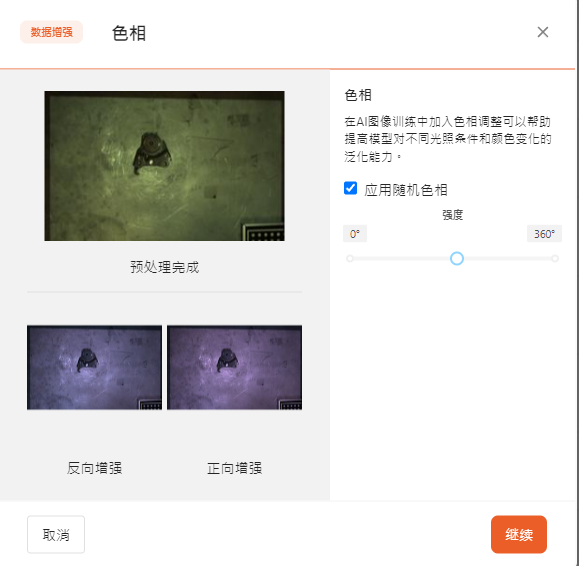
- 色相
在AI图像训练中加入色相调整可以帮助提高模型对不同光照条件和颜色变化的泛化能力。
可以滑动调整色相强度。
- 饱和度
在图像训练中家兔饱和度可以是训练模型更容易识别和学习图像中的关键特征,从而提高模型的准确性。
可以滑动调整饱和度强度。
- 饱和度增强
在图像训练中加入饱和增强可以使训练模型更容易的识别和学习图像中的关键特征,从而提高模型的准确性。
可以滑动调整饱和度增强强度。
- 对比度
通过变化图像对比度,帮助模型适应不同光照条件。
可以调整对比度最大值和可能行
- 噪声
通过添加噪声,帮助模型适应相机的伪影。
可以调整噪声的最大像素值和可能性。
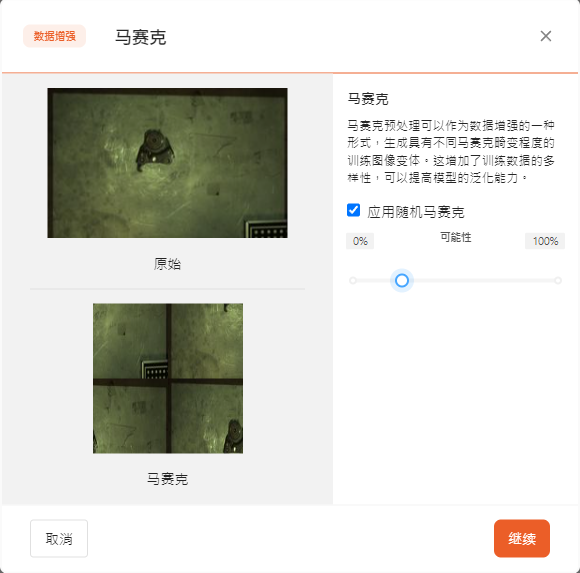
- 马赛克
马赛克预处理可以作为数据增强的一种形式,生成具有不同马赛克畸变程度的训练图像变体。增加寻来你数据的多样性,同时提高模型的泛化能力。
可以调整马赛克的可能性。
选择训练模式
在完成训练集创建之后,您可以开始在DaoAI World上训练您的模型。
对于每一个模型类型,我们都提供多种训练模式。可以按照模型使用场景及需求选择合适的训练模式。
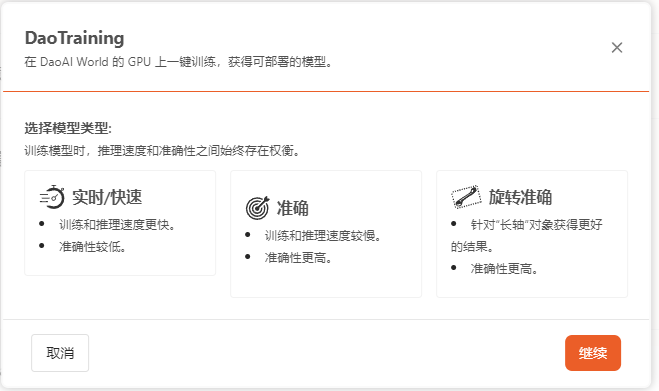
快速模式:
使用快速模式训练得到的模型,模型使用时识别速度更快,但是准确率可能会有所下降。
在使用场景对识别速度要求较高,但是对准角度的要求不高时,可以使用快速模式训练模型。
准确模式:
使用准确模式训练得到的模型,在使用时识别物体的准确率更高,但是识别速度较慢。
在使用场景对精确度要求较高时,可以使用准确模式训练模型。
旋转准确模式:
使用旋转准确模式训练得到的模型,在识别物体时准确度较高,同时对于被识别物体出现旋转的情况,也能够保持较高的识别准确度。
在使用场景对精度要求较高,并且被识别物体可能出现旋转的情况时,可以使用旋转准确模式训练模型。
在选择模式后,点击“继续”进入下一步。
- 选择训练标签:
- 在开始训练之前,您可以最后检查并确认所选的训练标签是否正确。如果数据是从其他项目导入的,可能会存在标签错误的情况。在这种情况下,您可以选择删除错误的标签,确保这些标签不会被纳入训练。
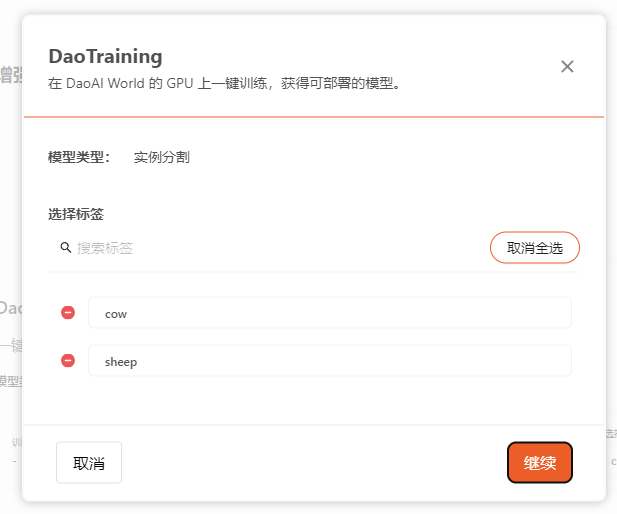
然后点击生成并开始训练即可启动训练过程。
各模型提供的训练模式
模型类型 |
快速模式 |
准确模式 |
旋转准确模式 |
|---|---|---|---|
实例分割检测 |
√ |
√ |
√ |
关键点检测 |
√ |
√ |
√ |
异常检测 |
√ |
√ |
|
分类检测 |
√ |
√ |
|
目标检测 |
√ |
√ |
√ |
语义分割 |
√ |
||
OCR |
√ |
实时训练图
训练过程中,您可以看到模型的实时训练结果图。
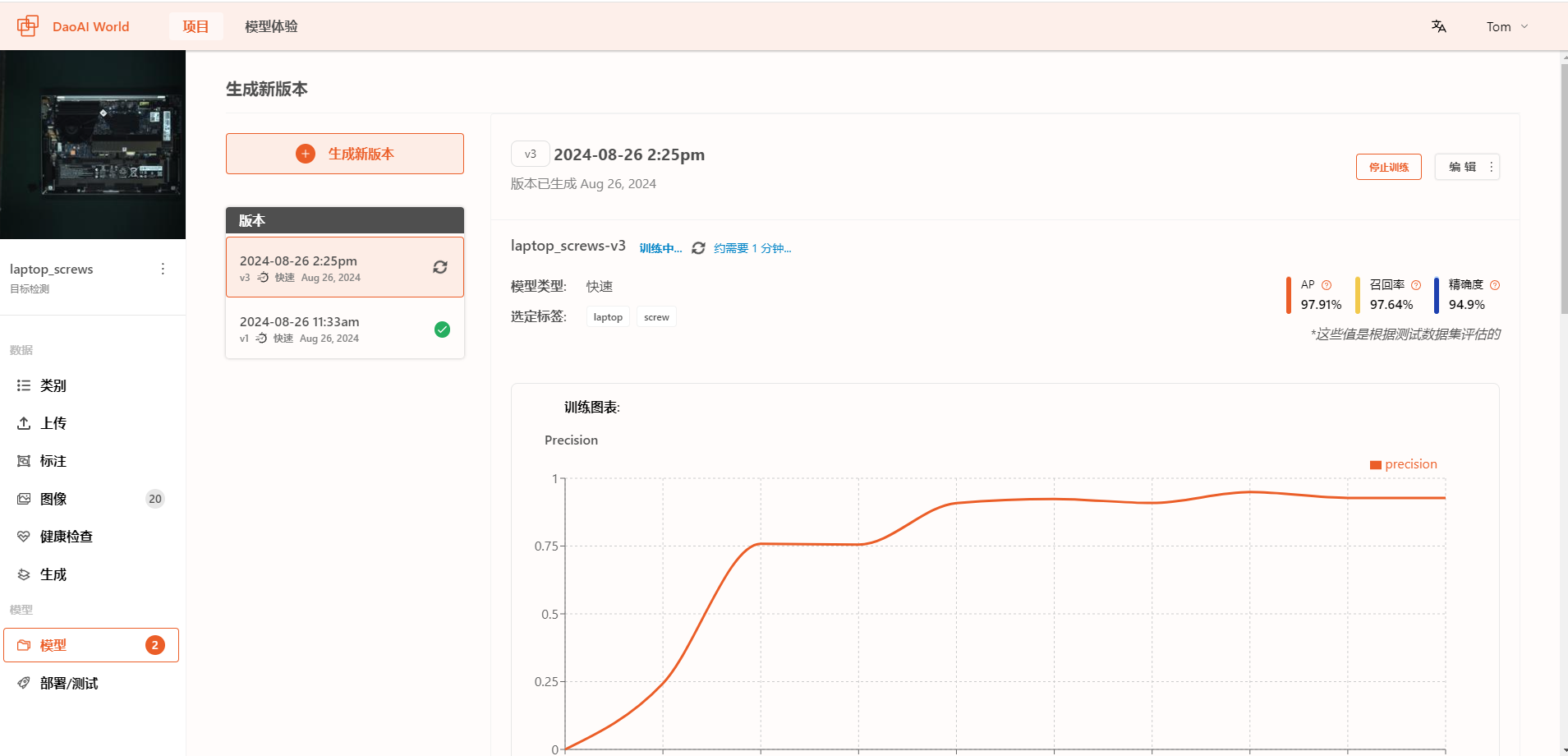
这里可以查看训练的预计剩余时间,以及实时的训练准确率。
如何训练出好的模型?
首先,什么是“好的模型”呢?
好的模型应该是识别结果正确的模型,是一个稳定的模型,可以处理更多复杂情况的模型,更应该是一个可以按照用户的目的完成识别的模型。
根据上述的这几点,我们怎么才能训练出一个好的模型?这个页面会给你一些基本的概念,有什么东西你是需要提前去思考的,详细的内容可以在每个章节底下找到。
你需要选取哪一种模型以达到你的目标?
深度学习功能非常强大,但是每个模型的专注强项也不一样,你需要先从你的使用上考虑,你需要什么样的识别结果?你可以询问一下自己,从实际出发,回答以下问题:
如果你需要的是识别多种物体,需要所有物体的精确位置,不需要精确的物体方向,那么很大几率你需要的是 实例分割检测 。
如果你需要的是识别多种物体,需要所有物体的精确位置,而且物体方向信息非常重要,那么很大几率你需要的是 关键点检测 。
如果你只需要的是单种物体的状态,检查物体是否存在异常,不需要物体的精确位置和方向信息,那么很大几率你需要的是 异常检测 。
如果你需要的是当前物体的种类,不需要物体的精确位置和方向信息,那么很大几率你需要的是 分类检测 。
如果你需要的是识别多种物体以及数量,不需要所有物体的精确位置和方向信息,那么很大几率你需要的是 目标检测 。
如果你需要的是识别多种物体以及数量,而且物体方向信息非常重要,那么很大几率你需要的是 旋转目标检测 。
如果你只需要的是单种物体的状态,检查物体是否存在异常,并且需要知道异常的种类,那么很大几率你需要的是 语义分割 。
如果你需要提取图片中的文字,那么很大几率你需要的是 OCR 。
应该怎么去标注?
标注会影响你的模型最终的效果,一个好的模型是需要有好的标注作为基础。
标注的时候尽量仔细,不要出现漏标、错标的情况;这些错误会影响模型的识别,要注意。
应该添加什么预处理和数据增强方法?
当物体和背景的颜色或者对比度比较相似时,不论是模型还是人,都很难判断物体和背景的边界。
使用直方图均衡化:增强图像对比度,突出物体的边界。
思考:哪些模型 不可以 使用直方图均衡化呢?
物体检测模型:物体检测模型并不是说完全不可以使用直方图均衡化,然而是因为物体检测模型标注的方式:方框工具;标注的物体是存在于方框内,但方框内并不是完全只有物体,还会有部分的背景存在于方框中。
那么在使用直方图均衡化预处理时,并没有很好的把背景和物体分割出来。所以直方图均衡化预处理在物体检测模型上没有很好的效果。
添加翻转增强方式时,有什么需要注意的呢:
使用翻转对添加水平或垂直翻转时,需要注意你的物体是否会存在镜面翻转的该物体?
当物体是非对称物体时,翻转在一定程度能提高模型的效果。但是要注意的是,这个物体是否会以翻转的情况出现?
举个例子:模型需要检查印刷的文字是否有缺失。实际中是不会出现镜面翻转的文字,那么这个翻转增强就不可以使用在该模型上;
当物体是非对称而且左右/上下方向是识别的重要信息,那也不可以使用翻转增强:很多金属零件是有方向区别的,可能零件A水平翻转就成为了零件B。这些情况下都是不可以使用翻转增强的。
备注
所以,在添加任何预处理或者数据增强方法时,用户需要仔细考虑清楚实际的情况。
应该使用什么训练模式?
首先,部分模型是不支持旋转准确模式的。其次,我怎么去选择?
答案是在于项目本身的要求:是否对于识别的时间有严苛要求?是否对于识别的准确率有严苛要求?
当项目对于识别时间要求很严苛,允许的识别时间很短,那么你应该选用快速模式;
当项目对于识别的准确率有很高的要求,允许的容错很少,那么你应该选用准确模式;